QK norm is probably a free lunch
Gavin Leech’s Transformer++ is a great blog post. It documents the post-GPT-2 tweaks people have made to the transformer architecture. Leech’s criterion for including a tweak is the following: three of the five cutting-edge open-source architectures (Llama, Gemma, Qwen, DeepSeek, and Hunyuan) should use it.
When he wrote the blog post, QK normalization was used by none of the five models. I wrote this post to document that today, all of them do. And if you’re training a large-ish foundation model today, you probably should, too.
How QK norm is used today
I’ll begin with a brief explanation of what QK norm is. Recall that in self-attention, queries and keys are dotted to produce attention logits, which are then softmaxed to get attention weights. In “Scaling Vision Transformers to 22 Billion Parameters”, Mostafa Dehghani and other coauthors at Google Research observed that for deep models, attention logits become large. This causes attention weights to become almost one-hot, losing expressiveness and destabilizing training. Their solution is to apply LayerNorm to queries and keys before dotting them to get the attention logits.
The latest models in the five families above all normalize their queries and keys before the attention logit computation. However, instead of LayerNorm, they use RMSNorm. (This follows the general trend in LLM architectures of swapping out LayerNorm with RMSNorm. Both transform embeddings on a per-token basis. But LayerNorm subtracts the mean across the embedding dimension and divides by the variance, while RMSNorm simply divides by the root mean square (RMS) with no demeaning step. Turns out that magnitude control, which RMSNorm provides, is sufficient without the distribution-normalizing effects of LayerNorm.)
Llama 4
A Llama 4 technical report doesn’t exist, but you can see QK norm in the forward
pass of their Attention
module:
if self.use_qk_norm:
xq = rmsnorm(xq, self.norm_eps)
xk = rmsnorm(xk, self.norm_eps)
Gemma 3
The Gemma 3 technical report mentions using QK norm:
Inspired by Dehghani et al. (2023), Wortsman et al. (2023) and Chameleon Team (2024), we replace the soft-capping of Gemma 2 with QK-norm.
Here is the implementation in the initialization of their GemmaAttention
module:
self.query_norm = (
RMSNorm(self.head_dim, eps=config.rms_norm_eps)
if config.use_qk_norm
else None
)
self.key_norm = (
RMSNorm(self.head_dim, eps=config.rms_norm_eps)
if config.use_qk_norm
else None
)
And in the forward pass:
if self.query_norm is not None and self.key_norm is not None:
xq = self.query_norm(xq)
xk = self.key_norm(xk)
Qwen 3
The Qwen 3 technical report mentions:
[W]e remove QKV-bias used in Qwen2 (Yang et al., 2024a) and introduce QK-Norm (Dehghani et al., 2023) to the attention mechanism to ensure stable training for Qwen3.
In the initialization of their Qwen3Attention
module,
they have:
self.q_norm = Qwen3RMSNorm(self.head_dim, eps=config.rms_norm_eps) # unlike olmo, only on the head dim!
self.k_norm = Qwen3RMSNorm(self.head_dim, eps=config.rms_norm_eps) # thus post q_norm does not need reshape
And in the forward pass:
query_states = self.q_norm(self.q_proj(hidden_states).view(hidden_shape)).transpose(1, 2)
key_states = self.k_norm(self.k_proj(hidden_states).view(hidden_shape)).transpose(1, 2)
Hunyuan A13B
The Hunyuan A13B technical
report
doesn’t mention QK norm, but in the initialization of their HunYuanAttention
module,
you can see they implement it:
if self.use_qk_norm:
self.query_layernorm = HunYuanRMSNorm(self.head_dim, eps=config.rms_norm_eps)
self.key_layernorm = HunYuanRMSNorm(self.head_dim, eps=config.rms_norm_eps)
And in the forward pass:
if self.use_qk_norm:
query_states = self.query_layernorm(query_states)
key_states = self.key_layernorm(key_states)
DeepSeek V3
DeepSeek V3 is a special case since they use
multi-head latent attention (covered by
Welch Labs in this great video).
However, they do the next best thing to QK norm: they normalize the low-rank
query and KV representations. In the initialization of their MLA
module,
q_norm and kv_norm are defined as:
if self.q_lora_rank == 0:
self.wq = ColumnParallelLinear(self.dim, self.n_heads * self.qk_head_dim)
else:
self.wq_a = Linear(self.dim, self.q_lora_rank)
self.q_norm = RMSNorm(self.q_lora_rank)
self.wq_b = ColumnParallelLinear(self.q_lora_rank, self.n_heads * self.qk_head_dim)
self.wkv_a = Linear(self.dim, self.kv_lora_rank + self.qk_rope_head_dim)
self.kv_norm = RMSNorm(self.kv_lora_rank)
And in the forward pass, q_norm is used as:
q = self.wq_b(self.q_norm(self.wq_a(x)))
kv_norm is used in naive attention as:
kv = self.wkv_b(self.kv_norm(kv))
In the absorbing attention implementation, kv_norm is used as:
self.kv_cache[:bsz, start_pos:end_pos] = self.kv_norm(kv)
Should you use QK norm?
It certainly seems that you can get away with not using QK norm. For example, Arcee AFM-4.5B, released just days ago, doesn’t use QK norm, looking at their inference code. Perhaps their model is shallow enough that queries and keys don’t explode. But it seems you can’t be sure that you don’t need it. The most striking evidence for this comes from a tweet thread that David Hall of Stanford’s Center for Research on Foundation Models posted. The entire thread is worth reading, but the gist is that the Marin 32B pretraining run had a problem: frequent loss spikes.
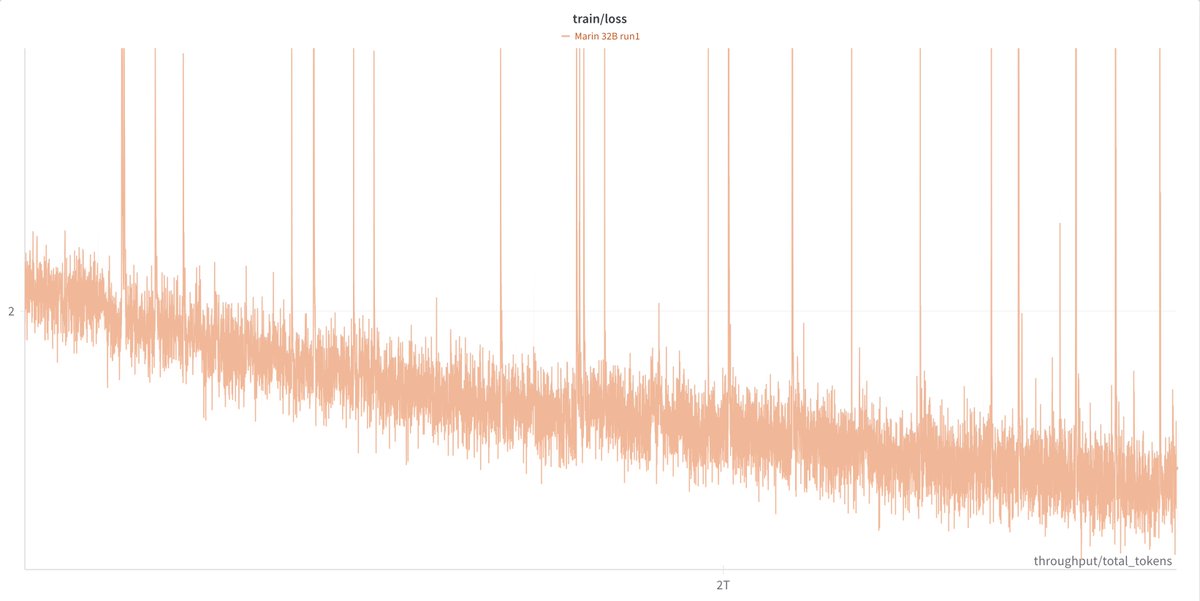
They tried a bunch of solutions: update clipping, loss and gradient outlier skipping, Muon, skipping the steps where the spike occurred, etc. Nothing worked. Then:
It was time to do what everyone else has learned but we were too proud, too foolish to try. (After all, the 22b and 70b trials were buttery smooth! Eval losses were ahead of schedule!) It was time to add QK Norm.
Adding QK norm not only fixed an irrecoverable loss spike, it’s also prevented spikes for the run so far:
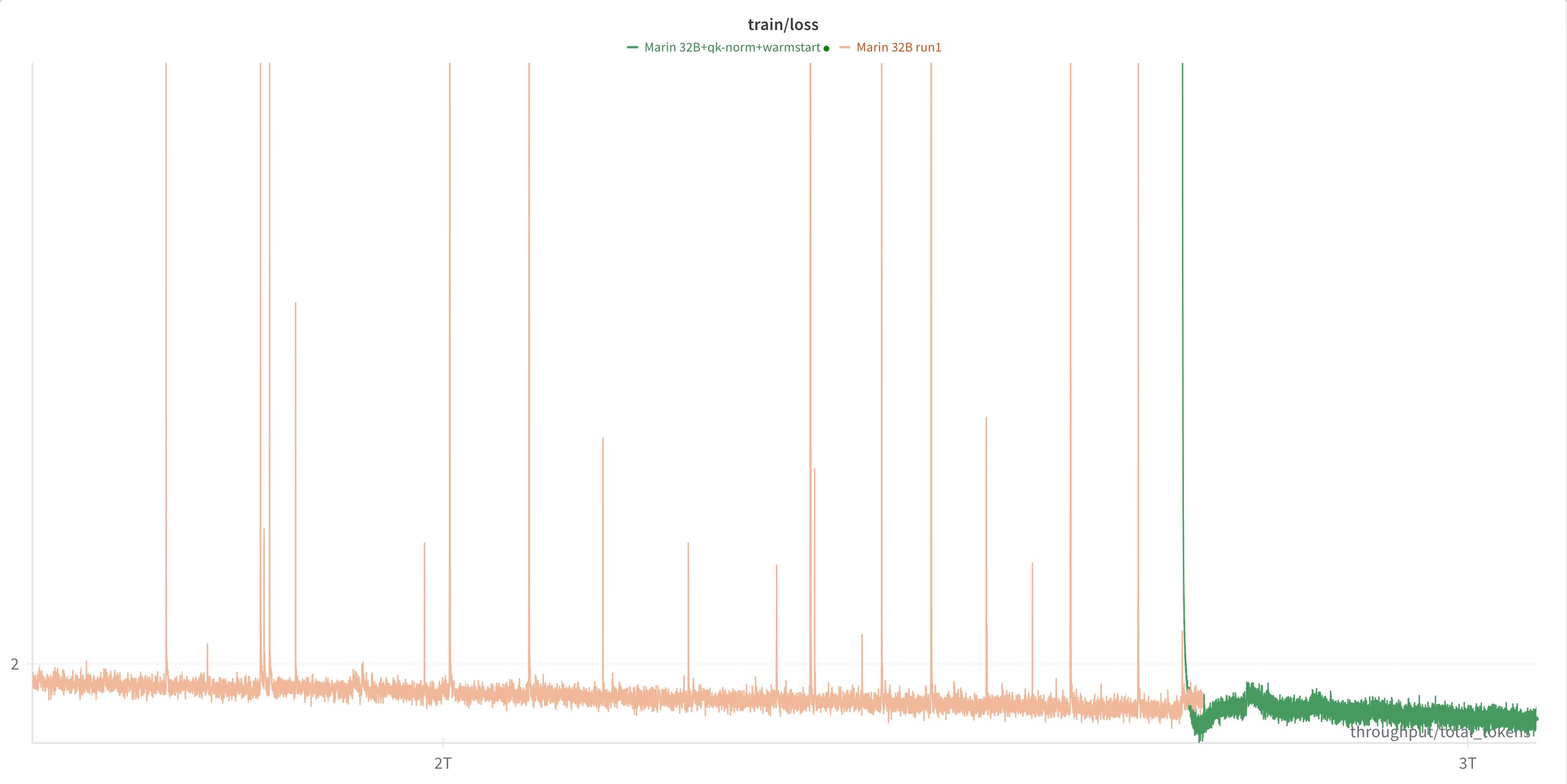
Hall writes:
Now, look, we knew QK Norm was a good idea. We just thought it wasn’t a **necessary** idea, not for us. We were different.
So, should you use QK norm? Yeah, probably. The tiny RMSNorm parameter and compute bloat seems worth the remarkable training stability. As Hall puts it, it seems “more norms good”. Here’s the meme summary of this tale (with, y’know, RMSNorm instead of LayerNorm):
