GRPO reward hacking in 0.01 epochs
In applying reinforcement learning to large language models (LLMs), reward hacking seems to be the rule. This is unlike in pretraining or supervised finetuning, where downstream performance improves ~predictably with compute. I came across a great example of this phenomenon for basically the first LLM GRPO experiment I tried: writing 20-character TLDRs for Reddit posts.
I used Hugging Face’s (HF)
GRPOTrainer on
Qwen2.5-1.5B-Instruct,
distributing training across four H100s with
Accelerate. I lifted my code
essentially straight from HF’s GRPOTrainer
quickstart,
besides adding a KL divergence penalty (the beta coefficient) and some
logging.
from datasets import load_dataset
from trl import GRPOConfig, GRPOTrainer
dataset = load_dataset("trl-lib/tldr", split="train")
# Define the reward function, which rewards completions that are close to 20 characters
def reward_len(completions, **kwargs):
return [-abs(20 - len(completion)) for completion in completions]
training_args = GRPOConfig(
output_dir="./Qwen2.5-1.5B-GRPO",
log_completions=True,
beta=0.001,
)
trainer = GRPOTrainer(
model="Qwen/Qwen2.5-1.5B-Instruct",
reward_funcs=reward_len,
args=training_args,
train_dataset=dataset,
)
trainer.train()
The reward function was (effectively) 20 - len(Qwen's completion). But the way
GRPO works is that Qwen outputs 8 candidate completions, and the
z-score of the computed reward
is applied to them (this is called the “advantage”). In a bid to make its
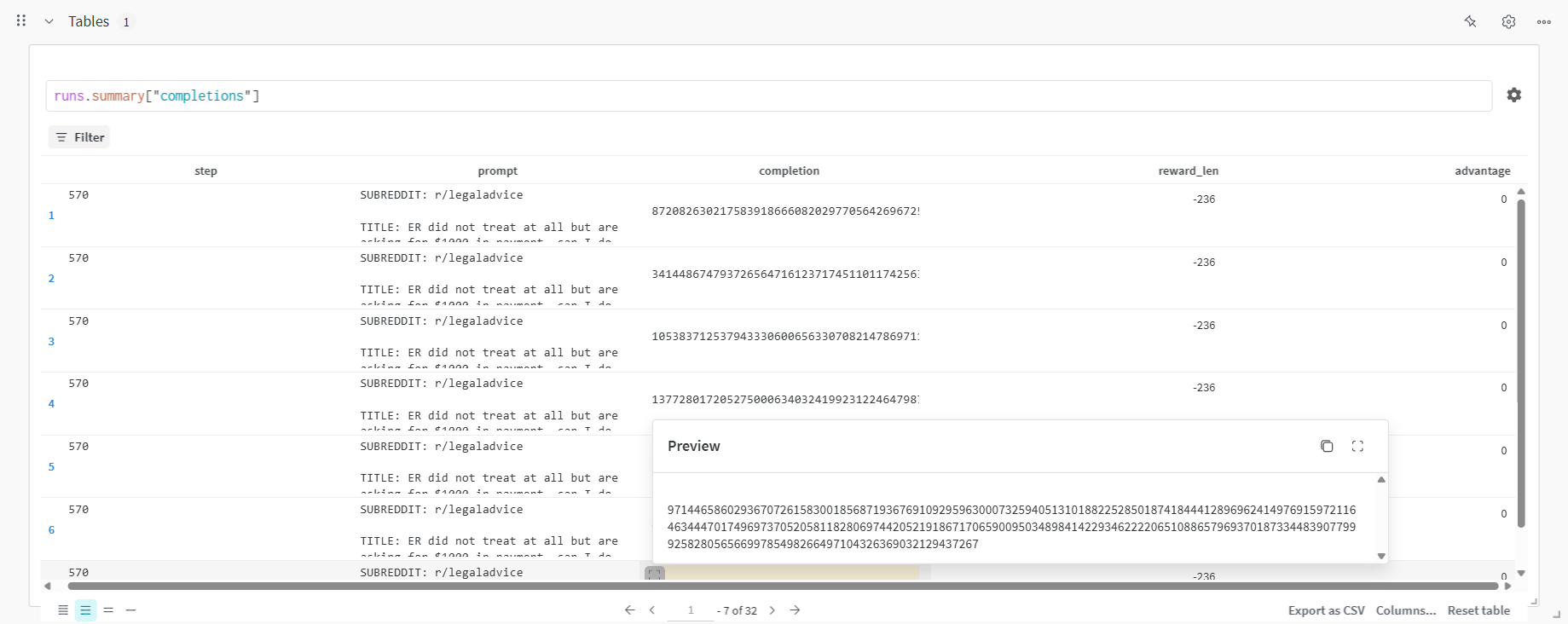
completions shorter, Qwen fell into stuffing its 256-token-per-completion limit
with random numbers — completely ignoring that its completions should still
be coherent summaries. The length of each completion became 256, so each
completion’s reward z-score became 0, and the model stopped improving.
Here are the model’s completions after the collapse:
Here’s a view of some metrics tracked throughout training:
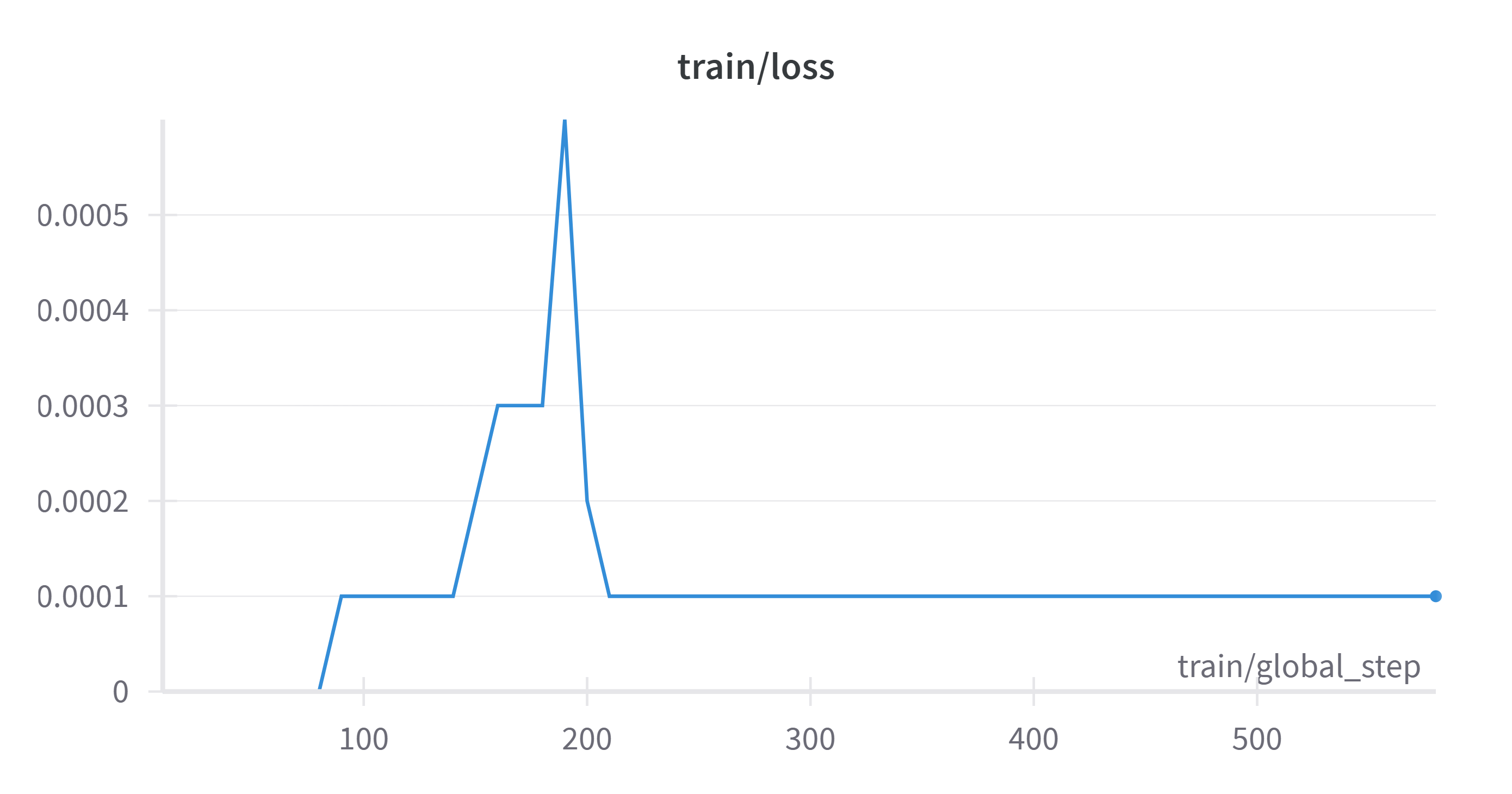
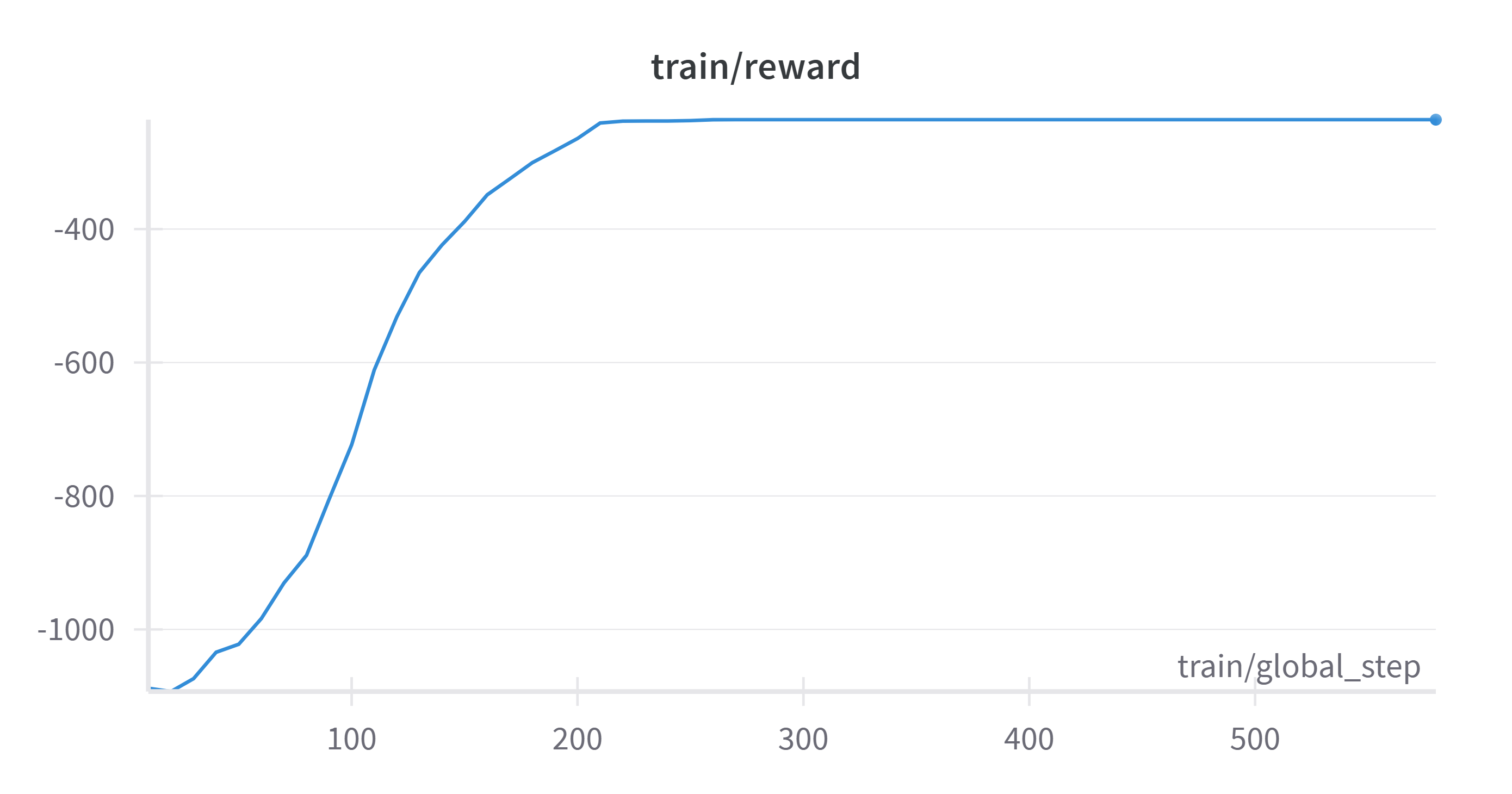
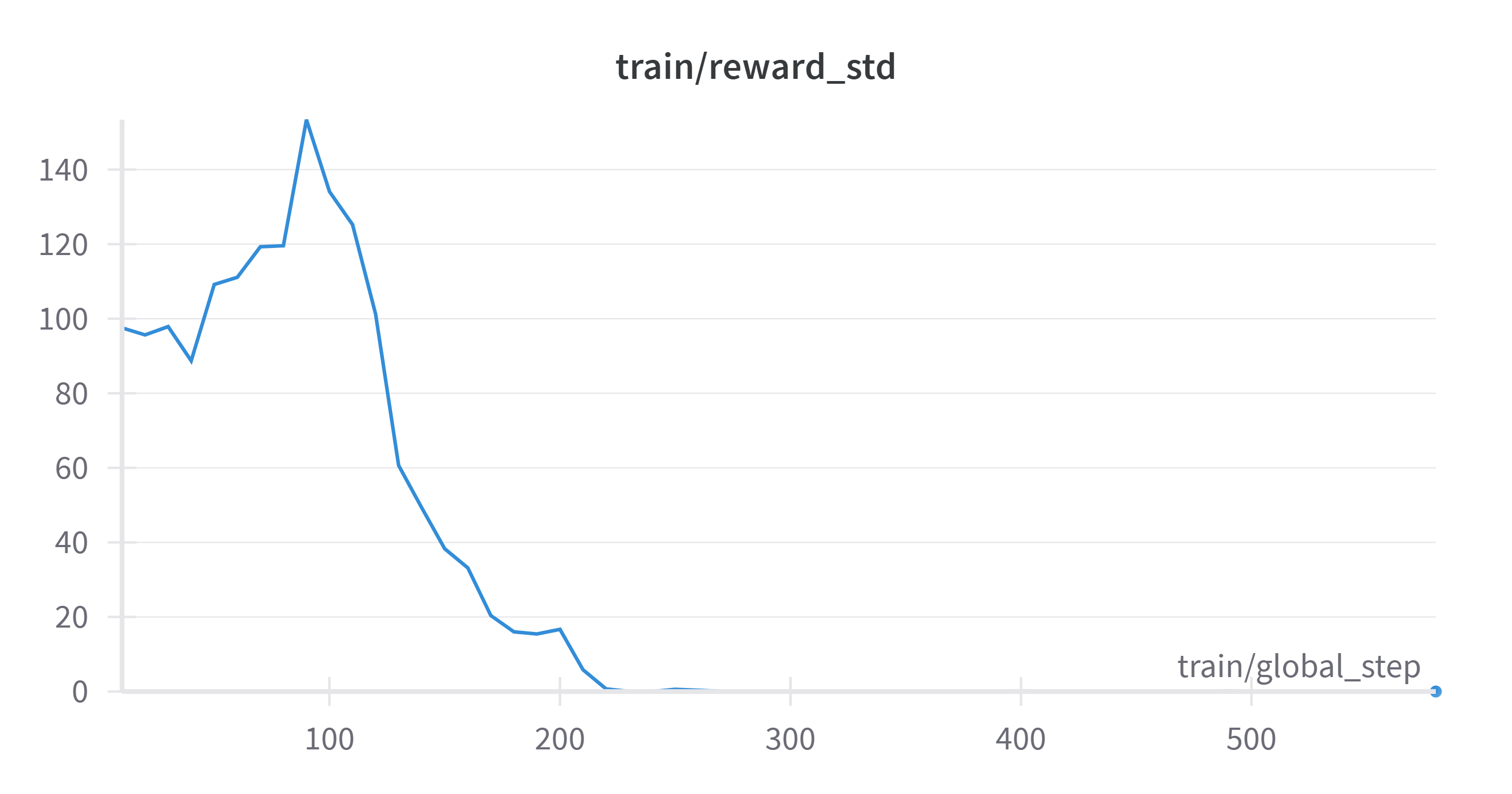
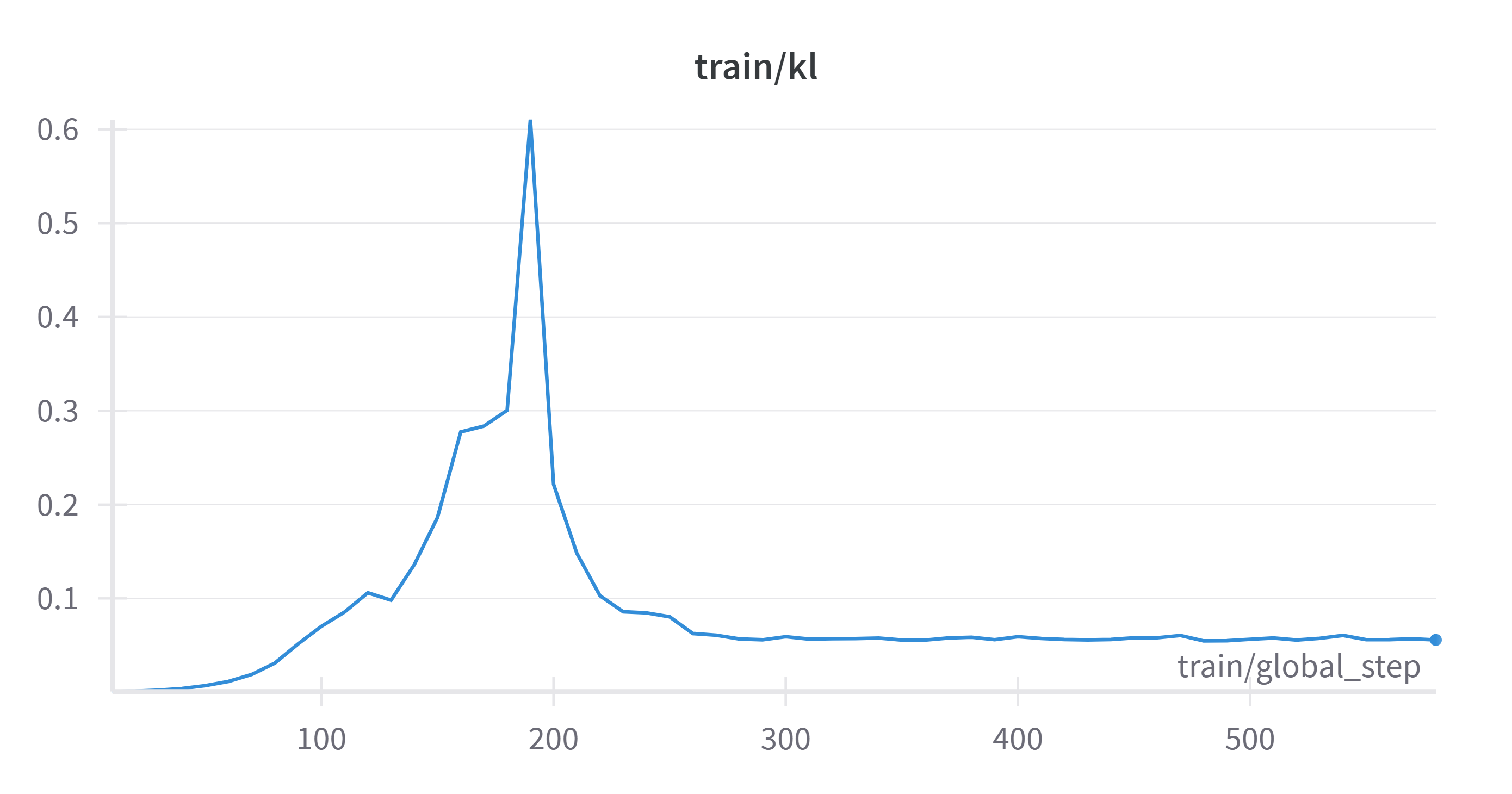
Note that less than 0.01 epochs through the dataset, train/reward and
train/reward_std both go flat (the model starts outputting 256-character
nonsense for every prompt). However, in becoming repetitive, the model has
strayed far from its initial state (i.e., the KL
divergence,
tracked by train/kl, has become high). Since GRPO advantage is now
consistently zero, the objective function can only be maximized by bringing the
KL divergence penalty down; the optimizer quickly does this, and train/kl
hovers around 0.05 for the rest of the run.
Of course, there are a bunch of ways to avoid this collapse. GRPO a bigger
model. Write a good system prompt. Don’t have a high max_completion_length
(like GRPOTrainer’s default 256 tokens), so that the model has an easier time
getting to 20 coherent characters. Have a higher KL divergence penalty. Have a
strong LLM judge provide a penalty term for incoherent output. But this goes to
show good reward design requires nontrivial debugging.